Proactive Cyber Defense with KillChainGraph
In this post, we’ll explore a machine learning framework designed to combine the attack flow from the Lockheed Cyber Kill Chain with the MITRE ATT&CK dataset, enabling better contextualization, prediction, and defense against adversarial behavior.

This post is a summarization of research conducted by Chitraksh Singh, Monisha Dhanraj, and Ken Huang in their paper “KillChainGraph: ML Framework for Predicting and Mapping ATT&CK Techniques”.
You can read their full paper on ArXiv here: https://arxiv.org/abs/2508.18230v1
Table of Contents
- Introduction
- What is MITRE ATT&CK?
- What is the Cyber Kill Chain?
- Why KillChainGraph?
- Methodology
- Dataset
- LightGBM (LGBM)
- Transformer
- BERT
- Graph Neural Network (GNN)
- Ensemble Strategy
- Semantic Mapping and Graph Construction
- Results
- Conclusion
Introduction
Conventional security tooling such as firewalls, rule-based intrusion detection systems, and signature-based analysis has long been the standard for security teams across the industry. It’s always been a cat-and-mouse game - as adversaries become more advanced, security professionals look for new ways to defend.
In addition to known threat actors and APT groups, advances in GenAI have led to a rise in sophisticated exploitation from unsophisticated actors. Just recently, Anthropic has documented the use of Claude to enhance cybercriminal operations and enable what they call “vibe hacking”, which is exactly what you think it is.
Defenders have been stuck playing catch up - most of the existing tooling they use operates reactively and are often ineffective against threats like zero day vulnerabilities and polymorphic malware. As adversaries become more advanced and the barrier to entry for sophisticated exploitation lowers, security professionals must adopt new techniques to stay ahead of the evolving threat landscape.
Recent works have shown success in using machine learning for intrusion detection and anomaly classification, allowing defenders to be proactive instead of reactive. This paper expands on that area of work by leveraging machine learning to combine the attacker lifecycle described by the Cyber Kill Chain (CKC) with adversarial techniques from MITRE ATT&CK. By mapping known ATT&CK techniques to phases of the CKC, we have all the information we need to contextualize, predict, and defend against an increasingly wide set of adversarial behavior.
In this paper, the researchers present a multi-model machine learning framework dubbed KillChainGraph that emulates adversarial behavior across the seven phases of the CKC using the ATT&CK Enterprise dataset. This machine learning approach offers a scalable solution for extracting behavioral insights from large volumes of cyber threat intelligence data, allowing defenders to proactively identify full-cycle attack paths and preemptively strengthen security controls.
What is MITRE ATT&CK?
ATT&CK is a globally accessible knowledge base maintained by the MITRE Corporation that houses detailed adversarial behavior. It catalogues known TTPs (Tools, Tactics, and Procedures) employed by threat actors based on real-world observations and is constantly updated as new TTPs are discovered. Security teams across the globe use this knowledge to understand, test, and defend against cyberattacks.
The ATT&CK Enterprise dataset is a full knowledge base of all the information MITRE maintains about adversary behavior in enterprise IT environments like Windows, Linux, MacOS, cloud, SaaS, containers, etc. - all in JSON format. This dataset contains:
- Tactics (High-level adversarial objectives i.e. initial access, persistence, privilege escalation)
- Techniques & Sub-techniques (Ways adversaries achieve each tactic along with detection ideas and mitigation advice)
- Groups (Threat Actors/APTs and which techniques they’ve been known to use)
- Software (Malware & Tools mapped to techniques)
- Mitigations (Defensive measures mapped to techniques)
- Relationships (Links that tie techniques <-> groups <-> software <-> mitigations)
What is the Cyber Kill Chain?
The Cyber Kill Chain was developed by Lockheed Martin as a way to break down the attacker lifecycle into 7 key phases. This allows defenders to understand how intrusions progress so they can detect, prevent, and disrupt attacks at different points.
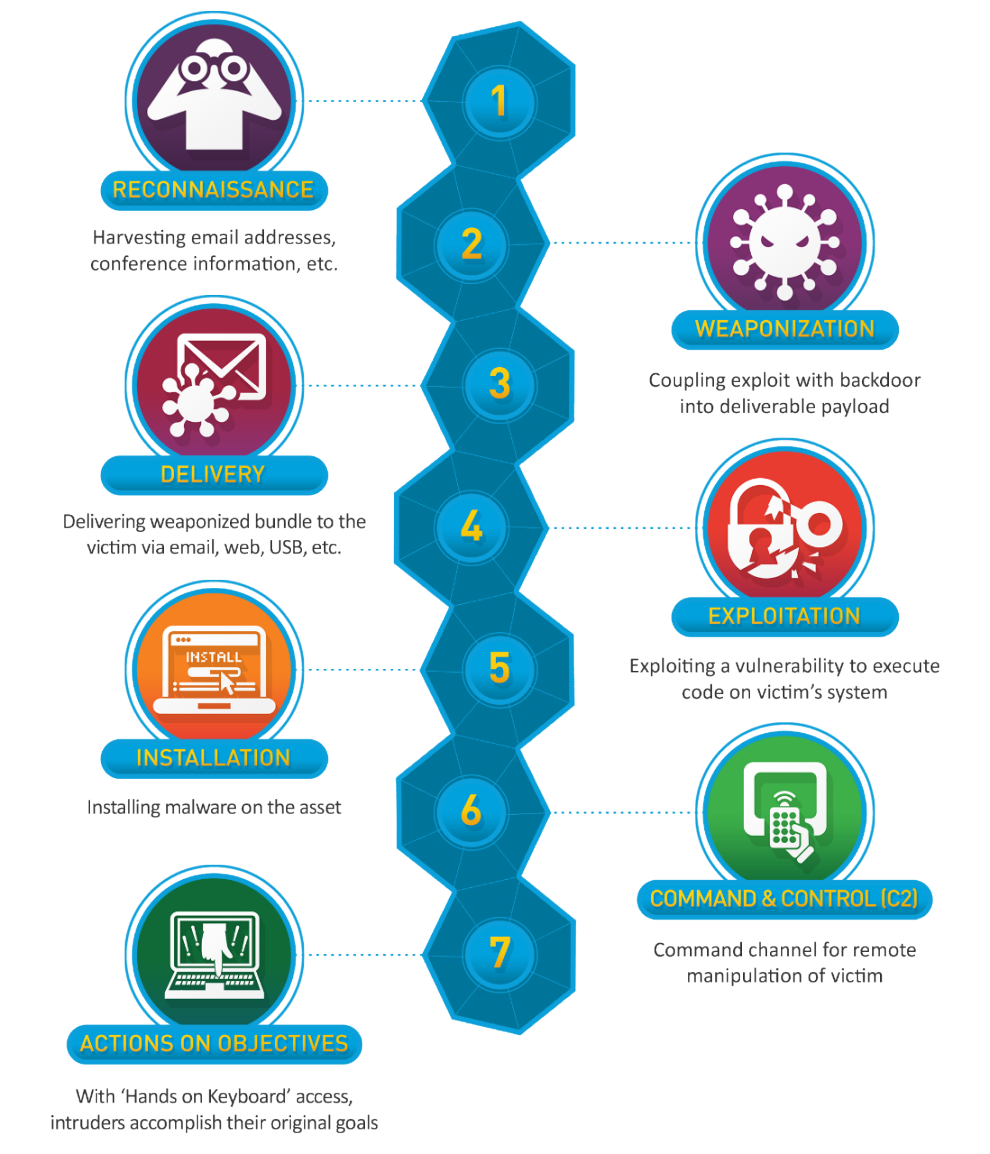
Lockheed Cyber Kill Chain Diagram (https://www.lockheedmartin.com/en-us/capabilities/cyber/cyber-kill-chain.html)
Why KillChainGraph?
The novelty of this approach is in producing phase-specific modeling aligned with structured frameworks (CKC and MITRE ATT&CK) already recognized by the security community. The researchers introduce a forward-predictive pipeline that models attacker progression across the CKC using a suite of supervised classifiers: LightGBM, Transformer, BERT, and GNN, each trained per CKC phase.
The input dataset was curated by semantically aligning ATT&CK techniques with CKC phases using ATTACK-BERT (a model specialized in understanding and analyzing cybersecurity-related text with a particular focus on attack actions and techniques). This generated phase-specific datasets that enable fine-grained classification of adversarial behavior.
The researchers then constructed a semantic similarity graph to link predicted techniques across phases, effectively simulating the attack pathing employed by threat actors. Combining this semantically guided data engineering and graph-based inference enables explainable reasoning over adversarial tactics, granting defenders increased situational awareness and the ability to proactively enhance cyber defense.
Methodology
The framework consists of two major components: dataset construction and model training.
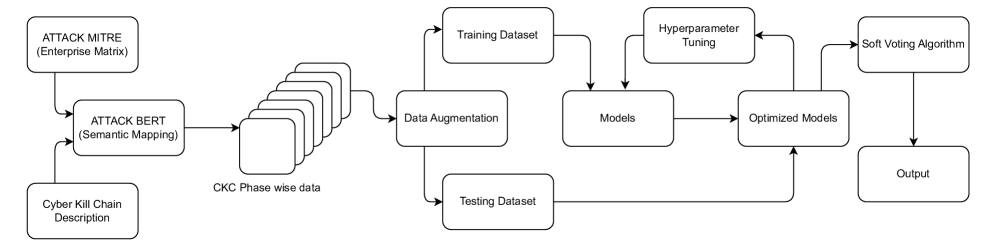
Five classification models are being employed:
- LightGBM (LGBM)
- Transformer
- BERT
- Graph Neural Network (GNN)
- Ensemble Strategy
Given attack descriptions, they are trained to predict which ATT&CK technique is being used along with its associated CKC phase. The results of which are then used to construct a graph representation of an adversary’s attack pathing.
Dataset
Using ATTACK-BERT, the researchers aligned adversarial behavior descriptions from the ATT&CK dataset with their appropriate CKC phase. This created a labeled dataset of adversarial actions, each consisting of an ATT&CK technique description, its corresponding ATT&CK technique ID + name, and the associated CKC phase. The dataset was then split into the seven CKC phases: Reconnaissance, Weaponization, Delivery, Exploitation, Installation, Command & Control, and Objectives.
After cleaning up the data, each of the seven datasets was stratified into training, validation, and testing sets in a 70-10-20 split with an emphasis on maintaining class balance wherever possible.
Phases like Delivery and Command & Control had limited data availability and class imbalance, so some data augmentation strategies were applied, such as:
- Synonym Substitution - increasing diversity in a dataset by replacing words in a text sample with their synonyms.
- TF-IDF Based Token Filtering - a mechanism to drop low-importance terms.
- Word Reordering and Controlled Duplication - another way to increase dataset diversity without altering underlying intent.
- Paraphrasing Techniques - methods like using a Pegasus model (trained to rewrite text with different words while preserving underlying intent) and back-translation (taking a sentence, translating it to another language, then back to English).
These augmentation strategies improved the robustness and generalization ability of models trained on low-resource CKC phases.
Given a description of an attack, each model is trained to predict the correct ATT&CK technique being used (and by extension its CKC phase).
Now, let’s take a look at each of the models the researchers used for this framework.
LightGBM (LGBM)
LightGBM works by building lots of small decision trees and combining them. The model essentially learns a bunch of little rules from the dataset like “if the word credential is present it most likely has to do with credential dumping” or “if the description mentions a registry it’s most likely a persistence technique” then combines these rules to guess the correct ATT&CK technique.
First, a vector embedding (an array of numbers) is generated using ATTACK-BERT to represent the semantic content of a given ATT&CK description. Then, they use this and its associated ATT&CK technique name to train the model. This allows the model to decide which specific ATT&CK technique is being employed, given a description of the attack.
Transformer
The Transformer-based classifier was another way for the researchers to classify ATT&CK techniques given a description. In this model, they used GloVe instead of ATTACK-BERT to generate semantic vector embeddings. Each vector embedding corresponding to a given attack description was given to the transformer as input.
The main difference in the transformer architecture is that instead of following a rigid “if-then” path like a decision tree, the Transformer uses a flexible neural network with self-attention to understand the meaning of the whole attack description even when important words are spread out.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model designed to capture deep bidirectional representations from unlabeled text. The researchers fine-tuned this pre-trained model on ATT&CK technique descriptions to predict the corresponding technique label.
Each description was tokenized (broken up and translated to numbers) and truncated/padded to a fixed sequence length. These tokens are fed into BERT to generate semantic vector embeddings, which are then passed to a function that outputs the probabilities for each possible ATT&CK technique label. The label with the highest probability is chosen and returned.
The main advantage of BERT is that there is a performance boost due to its pre-training on large-scale corpora like Wikipedia and BookCorpus. It has the ability to learn task-specific representations with minimal architectural modification and fine-tuning. This allows the model to better adapt to domain specific text - in our case: adversarial behavior descriptions.
Graph Neural Network (GNN)
The GNN in this framework is used to model the semantic and structural connections between ATT&CK descriptions. Each description is treated as a node in the graph, and the edges are constructed based on textual similarity (shared keyword patterns or how close the descriptions are in the semantic vector embedding space). A GNN layer aggregates information from neighboring nodes to update the representation of each node. The final node embedding is passed through a classification layer to predict the ATT&CK technique being used.
The main advantage of using a GNN is the ability to leverage the relational structure between technique descriptions, improving generalization for similar but rare classes. This is especially valuable in the context of cybersecurity, where techniques may have overlapping semantics and evolving terminology.
Ensemble Strategy
In this classifier, the four previous classification models (LGBM, Transformer, BERT, and GNN) are combined to synthesize a final ATT&CK technique prediction through a Weighted Soft Voting ensemble strategy. In a hard voting strategy, each classifier would give its prediction, and a majority vote would decide the final technique prediction. Soft voting decides the final technique prediction by considering the predicted class probabilities from each individual classifier - allowing the framework to make a more nuanced decision influenced by each model’s confidence.
Semantic Mapping and Graph Construction
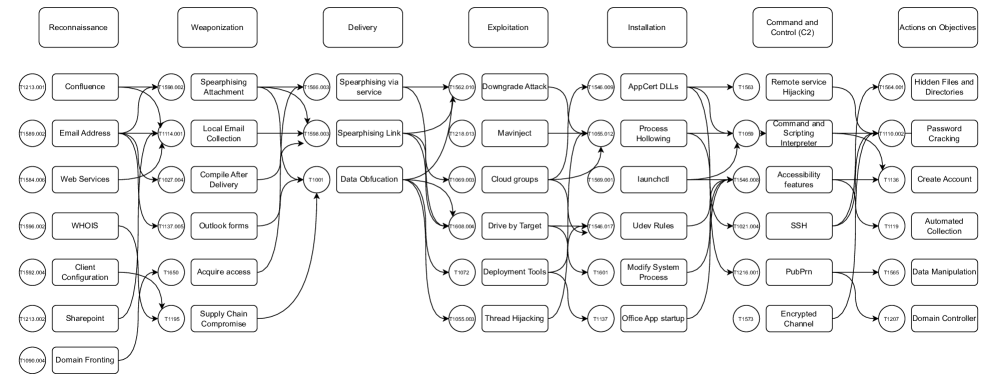
Once the final ATT&CK technique prediction has been generated, the next step is to construct a semantic graph that connects techniques across adjacent phases of the CKC. The goal is to simulate how an attacker might logically transition from one phase to the next.
Each attack description is converted into a vector embedding using ATTACK-BERT to capture semantic meaning. For any two techniques v_i from phase t and v_j from phase t + 1, we compute how similar they are using cosine similarity (how close the vector embeddings are in the vector embedding space). The resulting computation is a result where -1 <= result <= 1. 1 being perfectly similar and -1 being completely opposite. In this case, values closer to 1 indicate that the techniques are semantically similar and might represent a logical transition in an attacker’s plan.
To build the graph, a minimum threshold is set on result. If the similarity between two techniques across adjacent phases is greater than or equal to the threshold, we draw a directed edge from the earlier-phase technique t to the later-phase technique t + 1.
This semantic mapping helps model an attacker’s potential attack flow in accordance with the CKC, providing a structured view of predicted attacker behavior and aiding in proactive cyber defense.
Results
The researchers tested these five models (LightGBM, Transformer, BERT, GNN, and the ensemble strategy) across the seven CKC phases using the following metrics:
- Accuracy
- Precision
- Recall
- F1-score
The results were as follows:
- Ensemble Strategy 🏆
- GNN
- LGBM
- BERT
- Transformer
Overall, the ensemble strategy performed best. It’s important to note that its improvement over the GNN is small (0.03% - 0.20% gains) but significant given the already high baseline performance, where all F1-scores exceeded 97%.
For example, in the Delivery phase, the GNN achieves an F1-score of 99.28%, with the ensemble improving this to 99.31%, corresponding to a 0.03% increase. While in the Exploitation phase, the F1-score rises from 97.67% to 97.87% (a 0.2% gain). In the Installation phase, from 98.70% to 98.83% (a 0.13% gain). These improvements occur consistently across all phases, confirming that the ensemble provides incremental gains even when the GNN already performs near optimally.
GNN remains the strongest individual model, consistently outperforming LGBM, Transformer, and BERT across all metrics and phases.
LGBM generally ranks second, particularly in phases with clearer feature separability, while BERT performs better than Transformer due to its contextual semantic modeling, which is particularly beneficial in phases such as Exploitation and Delivery.
The Transformer model remains the weakest across all phases, with accuracies ranging from 55.56% in Delivery to 86.81% in Actions on Objectives, suggesting that self-attention architectures without domain-specific adaptation may underperform in this task.
The results indicate that while the GNN remains the most effective standalone classifier, the integration of multiple heterogeneous learners in a weighted soft voting framework produces a consistent performance uplift leading to fewer false positives and false negatives.
Conclusion
The researchers recognize that the ensemble model does require increased computational complexity and inference time due to the need for predictions from multiple models. However, the performance gains validate the effectiveness of their multi-model approach. Their future work will focus on real-world validation through live threat intelligence integration and deployment within automated SOC pipelines.
The ability to map and predict adversarial behavior is an essential building block for building truly effective defenses. In the meantime, these kinds of systems can help defenders visualize and contextualize adversarial activity into familiar frameworks - granting increased situational awareness and the ability to proactively take defensive measures.